◆ Micro Service Application Architecture
→ 로버트 C. 마틴(Robert C. Martin)은 클린 아키텍처에서 소프트웨어의 가치는 행위 가치와 구조 가치로 나뉘고 소프트웨어를 정말로 부드럽게(Soft) 만드는 것은 구조 가치라고 언급한 바 있는데 여기서 행위 가치는 소프트웨어의 기능을 말하며 구조 가치는 소프트웨어 아키텍처를 의미하는데 그는 토끼와 거북이의 경주를 예로 들며 가장 빨리 가는 방법은 제대로 가는 것이며 코드와 설계의 구조를 깔끔하게 만들려는 생각을 하지 않고 기능 구현만 목적으로 삼으면 소프트웨어가 엉망이 된 상황에 대처하는데 더 많은 비용이 든다는 점을 강조
→ 단기간의 프로젝트 동안 애플리케이션 구조나 설계에 신경 쓰지 않고 오직 기능 구현 에만 몰두한 소프트웨어는 전혀 소프트하지 않은데 새로운 형태의 UI나 기술을 추가해야 한다고 했을 때 거의 처음부터 새로운 시스템을 만드는 것과 같은 수준으로 수정해야 하고 사소한 기능 변경에도 변경의 파급효과 및 영향도를 알 수 없어 그에 따른 실제 변경 작업보다 다른 모듈의 영향도를 파악하기 위한 테스트에 더 많은 시간을 투자해야 함
→ 개발과 운영을 모두 책임지고 있는 Micro Service팀 입장에서는 소프트웨어의 초기 개발 뿐만 아니라 지속적인 비즈니스의 변화에 빠르게 대응할 수 있는 구조가 필요한데 소프트웨어가 부드럽지 않다면 기민하게 대응하기가 어려울 것
→ Micro Service 또한 작은 애플리케이션이므로 기존의 애플리케이션 아키텍처의 연장선에서 고려해야 함
◆ 비지니스 로직은 어디에 – 관심사의 분리
→ 소프트웨어의 핵심은 비즈니스 로직인데 비즈니스 로직이란 보통 시스템의 목적인 비즈니스 영역의 업무 규칙(Rule), 흐름(Flow), 개념(Concept)을 표현하는 용어
→ 개발자의 역할은 문제 영역의 비즈니스 로직을 분석 및 이해하고 프로그래밍 언어라는 도구로 잘 표현하는 일인데 여기서 잘 표현한다는 것은 기능이 잘 동작하는 것과 더불어 이해하기 쉽고 변경하기 쉬운 시스템을 만드는 것을 의미
→ 설계 원칙 중 관심사의 분리(separation of concerns)라는 원칙이 있는데 이것은 시스템의 각 영역이 처리하는 관심사가 분리되어 잘 관리돼야 한다는 의미이고 이 원칙은 시스템을 이해하고 변경하기 쉽게 만들어 주는데 이 원칙에 따라 각 영역은 고유 관심사에 의해 분리되고 집중돼야 함
→ 모듈화 및 계층화도 이 같은 원칙에 기인하는데 특히 비즈니스를 표현하는 비즈니스 로직 영역과 기술 문제를 처리하기 위한 기술 영역은 철저히 분리하는 것이 좋은데 이것은 비즈니스 로직이 기술보다는 오랫동안 지속되고 안정적이어야 할 애플리케이션의 핵심 영역이기에 기술에 영향을 적게 받도록 설계하는 것을 강조한 데서 기인
→ 기술과 비즈니스 로직을 분리했을 때 복잡성이 낮아지고 유지보수성도 높아짐
→ 객체지향 분석설계(OOAD: Object Oriented Analysis and Design)에서는 비즈니스 로직을 누가 봐도 이해하기 쉽게 구조화하는 객체 모델로 표현하는 것을 강조
→ 애플리케이션의 유지보수성이 높다는 의미는 특정 개인에 의존하기보다는 어느 누구라도 손쉽게 애플리케이션을 이해하고 유지보수 할 수 있음을 의미
→ 유연하고 확장성 있는 MSA시스템을 만들기 위해서는 각 Micro Service의 관계들을 유연하게 만드는 MSA 외부 아키텍처 및 패턴도 중요하지만 Micro Service의 내부 구조를 어떻게 유연하게 만들 것인지도 중요
→ 데이터베이스 중심 아키텍쳐의 문제점
● 데이터베이스 중심 아키텍처란 특정 관계형 데이터베이스에 의존한 데이터 모델링을 수행한 다음 이 물리 테이블 모델을 중심에 두고 애플리케이션을 구현하기 위한 사고를 하는 방식
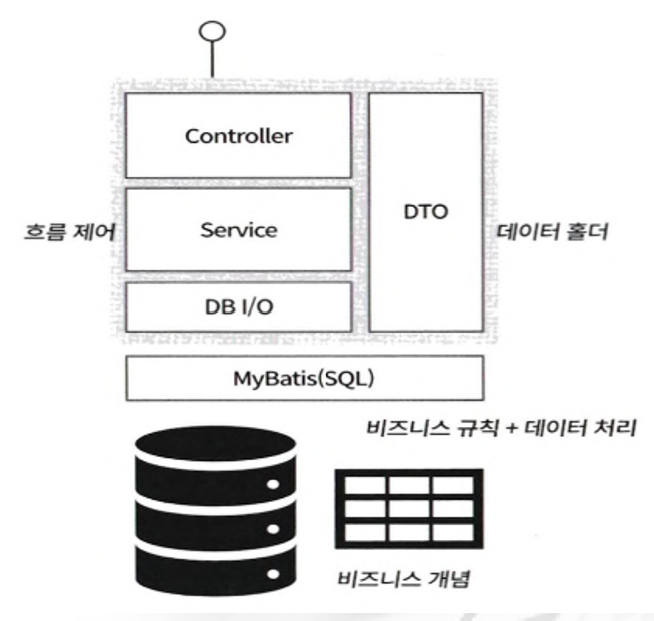
▶ 데이터베이스 중심 아키텍쳐의 문제점
● 일반적으로 스프링 프레임워크를 활용한다면 컨트롤러(Controller), 서비스(Service), DB I/O(Database Input/Output), DTO(Data Transfer Object)로 구성되고. 데이터 처리는 SQL 매핑 프레임워크인 마이바티스(MyBatis)를 사용
● 이러한 구조에서 일반적으로 비즈니스 로직은 서비스에 존재해야 한다고 말하지만 서비스에 존재하게 될 로직은 흐름 제어 로직 밖에 없고 그 밖의 비즈니스 개념과 규칙들은 앞에서 언급한 사례처럼 테이블과 SQL 질의에 존재
● DTO는 질의를 통해 가져오는 정보 묶음(information holder)의 역할밖에 할 수 없음
● 이 구조는 애플리케이션 로직 구성 패턴 중 하나인 트랜잭션 스크립트 구조와 비슷한데 간단한 처리 로직의 경우에는 편하지만 업무가 복잡해지면 점점 복잡성을 제어할 수 없게 된다는 단점이 있으며 업무 개념이 특정 저장 기술인 관계형 데이터베이스 테이블로 표현되고 업무가 복잡해질수록 업무 규칙이 데이터 질의 언어인 SQL과 섞여 표현
● 비즈니스 민첩성을 위해서는 유연성과 확장성이 중요하다고 한 바 있는데 한 회사에서 비즈니스의 특정 기능을 위해 읽기에 최적화된 NoSQL 저장소로 교체하기로 결정했 다고 하면 이러한 시스템 구조에서는 저장소를 변경하려고 해도 쉽게 변경할 수가 없는데 왜냐하면 저장 기술과 비즈니스 로직이 끈끈하게 붙어 있기 때문에 저장소를 변경했을 때 모든 것을 다시 구현해야 한다고 개발팀이 판단했기 때문
● 데이터베이스 중심 아키텍처의 성능 측면을 보면 이 같은 구조에서는 대부분의 성능을 데이터베이스에 의존
● 서비스의 비즈니스 개념과 규칙이 대부분 데이터베이스에 표현되기 때문이며 애플리케이션에서는 별로 할 일이 없기 때문에 데이터가 늘어남에 따라 데이터베이스의 성능은 지속적으로 떨어지게 되고 이를 최적화할 방법으로 데이터베이스 서버의 사양과 용 량을 계속 증가시키고 질의문 튜닝에 몰두할 수밖에 없는데 이렇게 되면 클라우드 인프라를 사용할 때 의 가장 큰 장점인 사용량에 유연하게 대응하는 자동 스케일 아웃이 의미가 없어지고 정작 바쁜 것은 데이터베이스이기 때문에 애플리케이션을 아무리 스케일 아웃해봐야 거둘 수 있는 효과가 미미
● 데이터베이스의 본질은 데이터 저장 처리이고 여기에 최적화돼 있으며 SQL도 비즈니스 로직을 처리하기 위한 언어가 아니라 데이터 처리에 최적화된 언어이므로 스토리지가 비싸고 한정적인 인프라 상황에서 최적의 성능을 발휘하기 위해 데이터베이스 중심의 아키텍처가 필요했던 시기가 있었지만 클라우드 시대에는 필요한 만큼 인프라를 유연하게 이용할 수 있고 저장 기술 또한 선택지가 다양하며 이전처럼 웹과 관계형 데이터베이스만 고려해야 하는 상황도 아니며 웹, 모바일, 명령형 인터페이스(CLI), IoT 기기 등 여러 디바이스의 입출력을 지원해야 하고 관계형 데이터베이스, 메모리 데이터베이스, NoSQL, 메시지 큐까지 다양한 저장소와의 연계가 필요
● 클라우드의 풍부한 자원 환경에서는 애플리케이션 자체의 성능보다는 애플리케이션의 확장성과 유연함이 더 중요하므로 관심사의 분리 원칙에 따라 끈끈하게 결합돼 있던 비즈니스 로직 처리와 데이터 처리를 철저히 분리하는 것이 반드시 필요
◆ 헥사고날 아키텍처와 클린 아키텍처
▶ 레이어드 아키텍쳐
● 레이어드 아키텍처(계층형 아키텍처)를 구성하는 레이어는 많은 사람들이 혼동하는 물리적인 티어의 개념과 달리 논리적인 개념
● 티어는 물리적인 장비나 서버 컴퓨터 등의 물리층을 의미하고 레이어는 티어 내부의 논리적인 분할을 의미
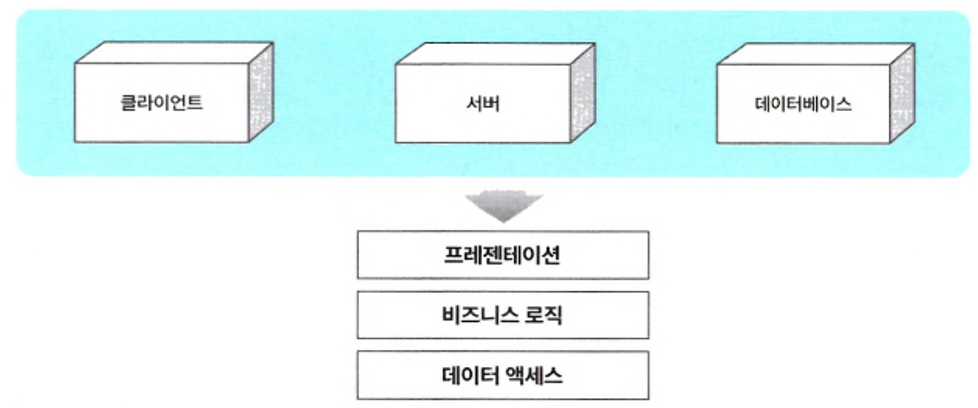
● 물리적인 서버 티어의 레이어를 프레젠테이션(presentation), 비즈니스 로직(business logic), 데이터 액세스(data access)의 3개의 논리적인 계층으로 구분할 수 있음
● 티어 와 레이어
● 계층은 설계자들이 복잡한 시스템을 분리할 때 흔히 사용하는 패턴 중 하나로 애플리케이션이 내부에서 처리하는 관심사를 논리적으로 구분
● 마틴 파울러가 엔터프라이즈 애플리케이션 아키텍처 패턴에서 구분한 레이어드 아키텍처 패턴의 전형적인 유형은 아키텍트가 의도하는 방향에 따라 여러 가지로 구분 가능하나 프레젠테이션, 비즈니스 로직, 데이터 액세스의 3계층으로 구분하는 것이 일반적

● 프레젠테이션 층의 관심사는 화면 표현 및 전환 처리이고 비즈니스 로직 층의 관심사는 비즈니스 개념 및 규칙, 흐름 제어이며 데이터 액세스 층의 관심사는 데이터 처리
● 레이어드 아키텍처는 레이어 간 응집성을 높이고 의존도를 낮추기 위해 다음과 같은 몇 가지 규칙을 둠
⊙ 상위 계층이 하위 계층을 호출하는 단방향성을 유지
⊙ 상위 계층은 하위의 여러 계층을 모두 알 필요없이 바로 밑의 근접 계층만 활용
⊙ 상위 계층이 하위 계층에 영향을 받지않게 구성
⊙ 하위 계층은 자신을 사용하는 상위 계층을 알지 못하게 구성
⊙ 계층 간의 호출은 인터페이스를 통해 호출하는 것이 바람직 - 구현 클래스에 직접 의존하지 않음으로써 약한 결합을 유지

● 인터페이스를 통한 의존성 분리는 인터페이스를 구현하는 구현체를 다양하게 해주는 다형성을 추구함으로써 제어 흐름을 간접적으로 전환하게 해줌
● 상위 계층은 직접적으로 하위 계층을 호출하지 않고 추상적인 인터페이스에 의존하는데 이 경우 하위 계층에서는 추상적 인터페이스를 만족하는 다양한 방식의 구현체를 선택적으로 적용할 수 있음
● 인터페이스 호출을 통한 다형성 추구

● 이러한 방식은 로버트 C. 마틴이 정의한 객체지향 설계 원칙 중 하나인 의존성 역전 원칙(DIP - Dependency Inversion Principle)을 만족하는 것처럼 보임
● 의존성 역전 원칙은 유연성이 극대화된 시스템에서는 소스코드 의존성이 추상에 의존하며 구체에는 의존하지 않아야 한다 를 뜻하기 때문
● 그렇지만 개방 폐쇄의 원칙(OCP; Open-Closed Principle)까지 살펴본다면 문제가 있는데 OCP는 소프트웨어 개체는 확장에는 열려 있어야 하고 변경에는 닫혀 있어야 한다는 원칙으로 이 원칙은 개체의 행위는 확장할 수 있어야 하지만 이때 개체를 변경해서는 안 된다는 의미
● 일반적인 레이어드 아키텍처에서 OCP가 위배되는 까닭은 모든 계층이 각기 자신이 제공하는 기능에 대한 추상적인 인터페이스를 직접 정의하고 소유하고 있는 구조이기 때문인데 이런 구조에서는 제어 흐름(flow of control)이 상위 계층에서 하위 계층으로 흐르게 되고 이에 따른 소스 코드의 의존성은 제어 흐름의 방향대로 따를 수밖에 없음
● 상위 계층은 하위 계층의 구체 클래스가 아닌 추상 인터페이스에 의존하고 인터페이스의 구현체를 달리하는 방법으로 의존성을 줄이고 다형성은 유지되나 인터페이스는 그 계층이 정의하는 추상 특성의 한계를 벗어날 수 없기 때문에 하위 계층의 유형이 추가되어 확장될 때 닫혀 있어야 할 상위 계층이 하위 계층에서 정의한 특성에 영향을 받게 됨
● 프레젠테이션, 비즈니스 로직, 데이터 액세스의 3계층으로 살펴보면 맨 마지막에 있는 데이터 액세스 계층이 변경됐을 때 비즈니스 로직 계층이 변경되면 안되는데 데이터 액세스 계층의 구현체가 클래스 C에서 클래스 D로 교체된 경우에는 비즈니스 로직 계층은 영향을 받지 않겠지만 데이터 액세스 계층의 인터페이스 B가 변경되면 비즈니스 로직 계층의 클래스가 데이터 액세스 계층의 인터페이스에 의존하기 때문에 변경의 영향을 받을 수밖에 없dma
● 문제는 데이터 액세스 인터페이스의 위치인데 데이터 액세스 인터페이스는 데이터 액세스 계층에 존재하는데 일면 당연해 보이지만 이 위치 때문에 상위 계층이 하위 계층에 의존하게 됨
● 애플리케이션에서는 비즈니스 로직이 핵심 영역이기 때문에 비즈니스 로직을 보통 고 수준 영역이라고 하고 프레젠테이션 계층 및 데이터 액세스 계층을 저수준 영역이라고 하는데 고수준 영역은 핵심 영역이므로 보호를 받아야 하고 저수준 영역의 변경이나 확장에 영향을 받지 않아야 하지만 일반적인 레이어드 아키텍처의 규칙만 따르면 고 수준 영역이 저수준 영역에 의존하게 되고 영향을 받게 되는데 여기서 의존성 역전 원칙(DIP)을 제대로 적용할 필요가 생김
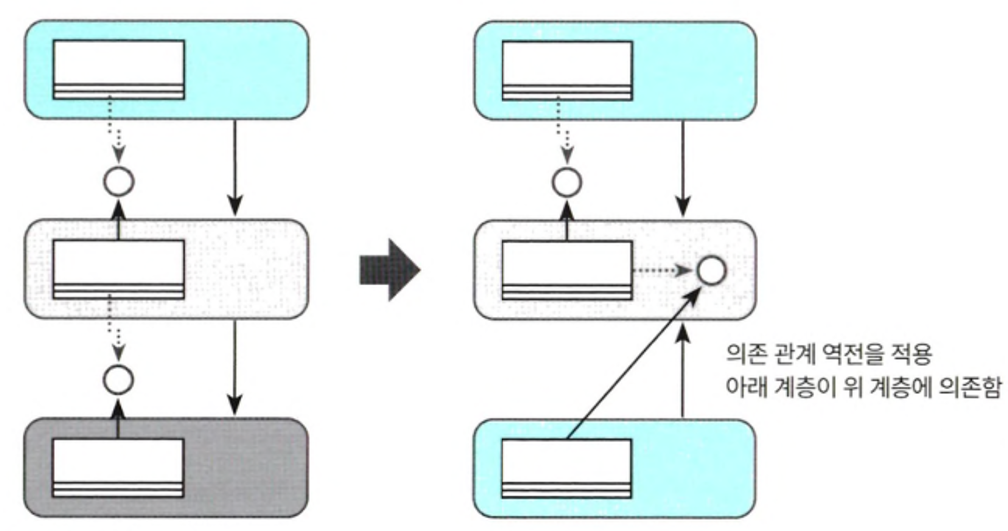
● DIP를 적용해 데이터 액세스 계층에서 정의한 인터페이스를 경계를 넘어 비즈니스 로직 계층으로 옮기면 데이터 액세스 계층의 구현체는 비즈니스 로직의 계층의 인터페이스를 바라볼 수밖에 없는데 데이터 액세스 계층이 구현해야 할 인터페이스를 좀 더 고수준의 비즈니스 로직 계층에서 정의하게 함으로써 기존의 위에서 아래로 흘렀던 의존 관계를 역전시키고 고수준 영역이 저수준 영역의 변경에 영향을 받지 않게 하는 것
● 의존 관계 역전의 적용
▶ 헥사고날 아키텍쳐
● 레이어드 아키텍처에 DIP를 적용해도 한계가 있는데 프레젠테이션 계층과 데이터 액세스 계층을 보통 저수준 계층으로 정의한다고 했는데 현대 애플리케이션에서는 이러한 두 가지 계층 말고도 다양한 인터페이스를 필요로 하는데 애플리케이션을 호출하는 다양한 시스템의 유형과 애플리케이션과 상호작용하는 다양한 저장소가 존재
● 단방향 계층구조에서는 이러한 점을 지원하기 힘들기 때문에 다방면으로 열려있는 헥사고날 아키텍처로 이러한 문제점을 해결
● 헥사고날 아키텍쳐
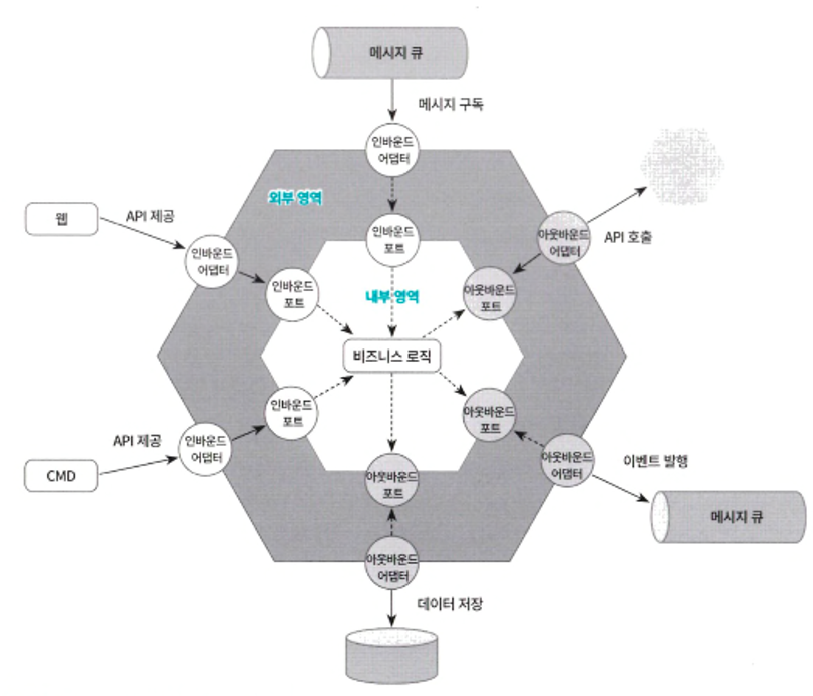
● 헥사고날 아키텍처는 앨리스테어 콕번(Alistair Cockburn)이 제시한 아키텍처로서 포트 앤드 어댑터 아키텍처(ports and adapters architecture)라고도 하는데 간단히 살펴보면 헥사고날 아키텍처에서는 고수준의 비즈니스 로직을 표현하는 내부 영역과 인터페이스 처리를 담당하는 저수준의 외부 영역으로 나누고 내부 영역은 순수한 비즈니스 로직을 표현하는 기술 독립적인 영역이고 외부 영역과 연계되는 포트를 가지고 있으며 외부 영역은 외부에서 들어오는 요청을 처리하는 인바운드 어댑터(inbound adapter)와 비즈니스 로직에 의해 호출되어 외부와 연계되는 아웃바운드 어댑터(outbound adapter)로 구성
● 헥사고날 아키텍처의 가장 큰 특징은 고수준의 내부 영역이 외부의 구체 어댑터에 전혀 의존하지 않게 한다는 것으로 이를 가능하게 하는 것이 내부 영역에 구성되는 포트
● 포트는 인바운드/아웃바운드 포트로 구분되는데 인바운드 포트는 내부 영역의 사용을 위해 표출된 API이며 외부 영역의 인바운드 어댑터가 호출하며 아웃바운드 포트는 내부 영역이 외부를 호출하는 방법을 정의하는데 여기서 DIP 원칙과 같이 아웃바운드 포트가 외부의 아웃바운드 어댑터를 호출해서 외부 시스템과 연계하는 것이 아니라 아웃바운드 어댑터가 아웃바운드 포트에 의존해서 구현
● 외부 영역에 존재하는 어댑터의 종류를 살펴보면 인바운드 어댑터로는 REST API를 발행하는 컨트롤러, 웹 페이지를 구성하는 스프링 MVC 컨트롤러, 커맨드 핸들러, 이벤트 메시지 구독 핸들러 등이 될 수 있고 아웃바운드 어댑터로는 데이터 액세스 처리를 담당하는 DAO, 이벤트 메시지를 발행하는 클래스, 외부 서비스를 호출하는 프락시 등이 될 수 있음
▶ 클린 아키텍쳐
● 클린 아키텍처는 로버트 c. 마틴이 제안한 아키텍처로서 헥사고날 아키텍처의 아이디어와 매우 유사
● 마틴은 소프트웨어는 행위 가치와 구조 가치의 두 종류의 가치를 가지며 구조 가치가 더 중요하다고 말하는데 소프트웨어를 부드럽게 만드는 것이 구조 가치이기 때문
● 소프트웨어를 부드럽게 유지하는 방법은 구조 중에서 선택할 수 있는 것을 가능한 한 오랫동안 열어두는 것인데 열어둬야 할 선택 사항은 중요하지 않은 세부 사항
● 마틴은 클린 아키텍처를 여러 겹으로 둘러싸인 영역으로 표현하며 중앙에서부터 밖으로 엔티티, 유스케이스, 그 외 세부 사항으로 구분
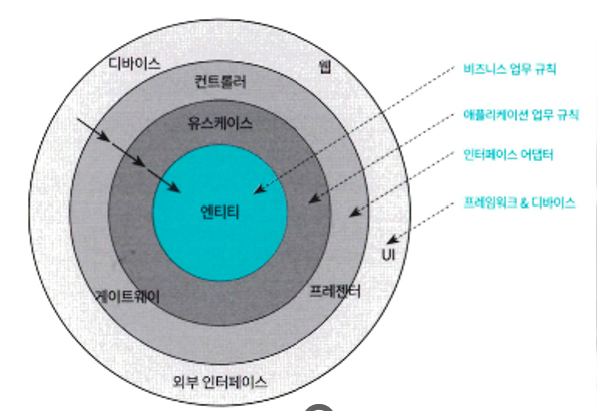
● 정중앙에는 엔티티가 있는데 업무 규칙은 사업적으로 수익을 얻거나 비용을 줄일 수 있는 규칙 또는 절차를 의미하며 이러한 업무 규칙은 수동으로 처리할 수 있지만 시스템으로도 자동화할 수 있는데 예를 들면 쇼핑몰의 물건을 사고 파는 규칙, 은행의 이자 계산 규칙, 도서대출 시스템의 대출/반납 규칙 등 모든 시스템에는 해당 도메인의 업무를 규정하는 핵심 업무 규칙이 존재하고 핵심 업무 규칙은 보통 데이터를 요구하므로 핵심 규칙과 데이터는 본질적으로 결합돼 있기 때문에 객체로 쉽게 만들 수 있는데 이러한 유형을 엔티티 객체라 함
● 엔티티를 감싸는 객체는 유스케이스(use case) 인데 유스케이스는 자동화된 시스템을 사용하는 처리 절차를 기술하는데 유스케이스는 애플리케이션에 특화된 업무 규칙을 표현하며 엔티티 내부의 핵심 업무 규칙을 호출하며 시스템을 사용하는 흐름을 담고 이때 엔티티 같은 고수준 영역은 저수준의 유스케이스 영역을 알게 해서는 안되고 엔티티는 간단한 객체여야 하며 프레임워크 데이터베이스 또는 기타 복잡한 것에 의존해서는 안 되고 유스케이스 객체를 통해서만 조작해야 하고 그 다음으로 유스케이스를 감싸고 있는 나머지 모든 영역이 세부사항
● 세부사항으로는 입출력 장치, 저장소, 웹 시스템, 서버, 프레임워크, 통신 프로토콜이 될 수 있으며 세부 사항과 유스케이스의 관계를 의존 관계 역전의 원칙을 이용해 플러그인처럼 유연하게 처리해야 하는데 이처럼 명확한 결합의 분리는 테스트 용이성 및 개발 독립성, 배포 독립성을 강화할 수 있음




댓글